
Last week, I presented a simple schema for organizing a comic collection. At the heart of the schema is the idea of a many-to-many relationship between publications and stories. That is to say that a given story can appear in many publications and a given publication may contain many stories. This many-to-many relationship is mapped into three tables that are ‘linked’ together in a relational database. The first table contains all the information about each publication. The second contains all the information about each story. The third table contains all of the relationships between the two.
In this post, I am going to present my particular implementation of this schema, and talk about some of its strengths and weaknesses. While the tables I’ll be presenting will have a lot more information in them than the basic ones presented in the last post, the basic approach remains the same. The additional information is provided to make the database much more useful and rich in the kinds of queries that can be made.
The database (technically a relational database management system or DBMS) that I use is Microsoft Access, which usually comes with the professional MS Office Suite. There are freeware alternatives to Access including MY SQL and LibreOffice Base, which work just as well if not better and, in my experience, moving the tables between tools is almost painless.
Let’s start with the Publication Table. In my implementation, each publication has 10 attributes corresponding to the 10 columns in the table, which, in the language of relational databases, are called fields. Each field has a name and a data type (integer, string, etc.) that specifies what kind of data it is. A record is a row in the table where a field takes on a particular value. The names, data types, and explanation of the fields in the Publication Table are:
| Field Name | Type | Meaning |
| Publication | Integer | A unique publication id label. No two Publication values can be the same, and the specific value is assigned by the DBMS unless overridden. |
| Publisher | String | Identifies the publishing house (Dark Horse, DC, Marvel, etc.) |
| Title | String | The title of the publication, usually as it appears in the indicia. |
| Number | Integer | The issue number as it appears in the indicia, or the value 1 if none is given. |
| Vol | Integer | The publication volume as it appears in the indicia, or the value 1 is none is given. |
| Year | Integer | The publication year as it appears in the indicia. |
| Type | String | Lists the type of publication. Usual values are ‘Comic’, ‘Trade’, or ‘Trade Paperback’, ’Trade/B&W’, ‘Glossy’, but they can be any string desired. |
| Condition | String | List the condition. I use only ‘Good’, ‘Fair’, and ‘Coverless’, but any string including CCG labels can be used. |
| Box | Integer | Identifies in which box the publication can be found. A value of 0 means on a book shelf. |
| copies | Integer | Number of copies. Occasionally I bought more than one by accident and so I needed this field. |
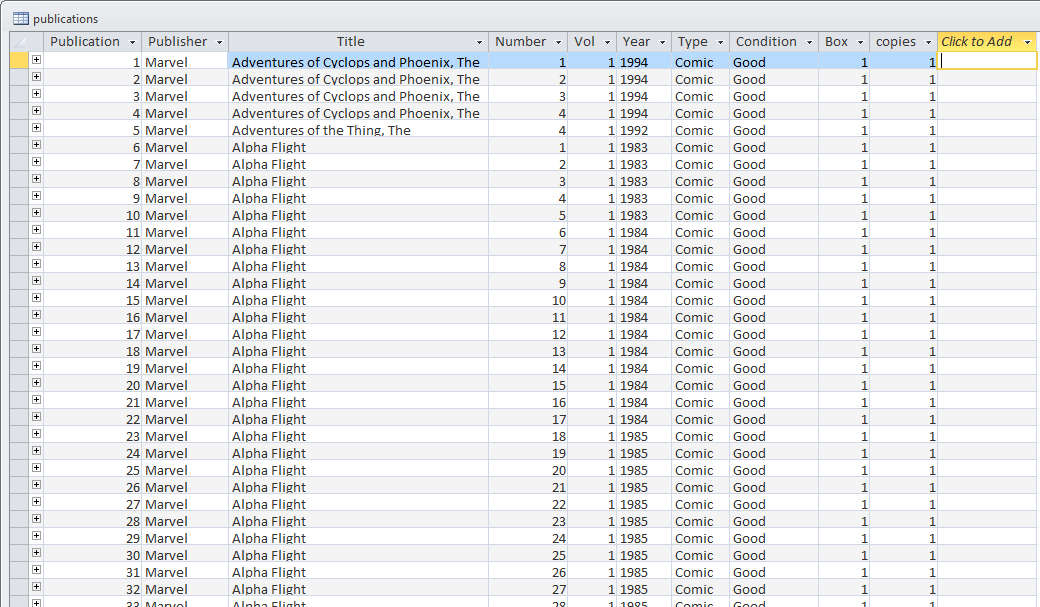
The following figure shows approximately the first 30 rows of the Publication Table.
Next is the Story Table. A story has 13 fields, and the names, data types, and explanations of these fields are:
| Field Name | Type | Meaning |
| Story | Integer | A unique story id label. No two Story values can be the same, and the specific value is assigned by the DBMS unless overridden. |
| Title | String | The title of the story as it appears in the original story. |
| Year | Integer | The year that the story was originally published. |
| Genre | String | Lists the key characters as I see it in a story. For example, a story with both Batman and Spider-man may have the string Batman & Spider-man as an entry |
| Author | String | Lists the names given author credit separated by a ‘,’ or an ‘&’ for multiple entries. No distinction is made between plot and dialog. |
| Illustrator | String | Lists the names given artist credit separated by a ‘,’ or an ‘&’ for multiple entries. |
| Inker | String | Lists the names given inker or finisher credits separated by a ‘,’ or an ‘&’ for multiple entries. |
| Original Comic Name | String | Lists the publication title in which the original story was found. |
| Original Comic Number | Integer | Lists the publication number in which the original story was found. |
| Original Comic Vol | Integer | Lists the publication volume in which the original story was found. |
| Read | Boolean/Checkbox | Yes or No value to track whether the comic has been read. |
| Cataloged | Boolean/Checkbox | Yes or No value to track whether the comic has been completely cataloged. |
| Variant | String | Special comment field to track changes in the story when reprinted. |
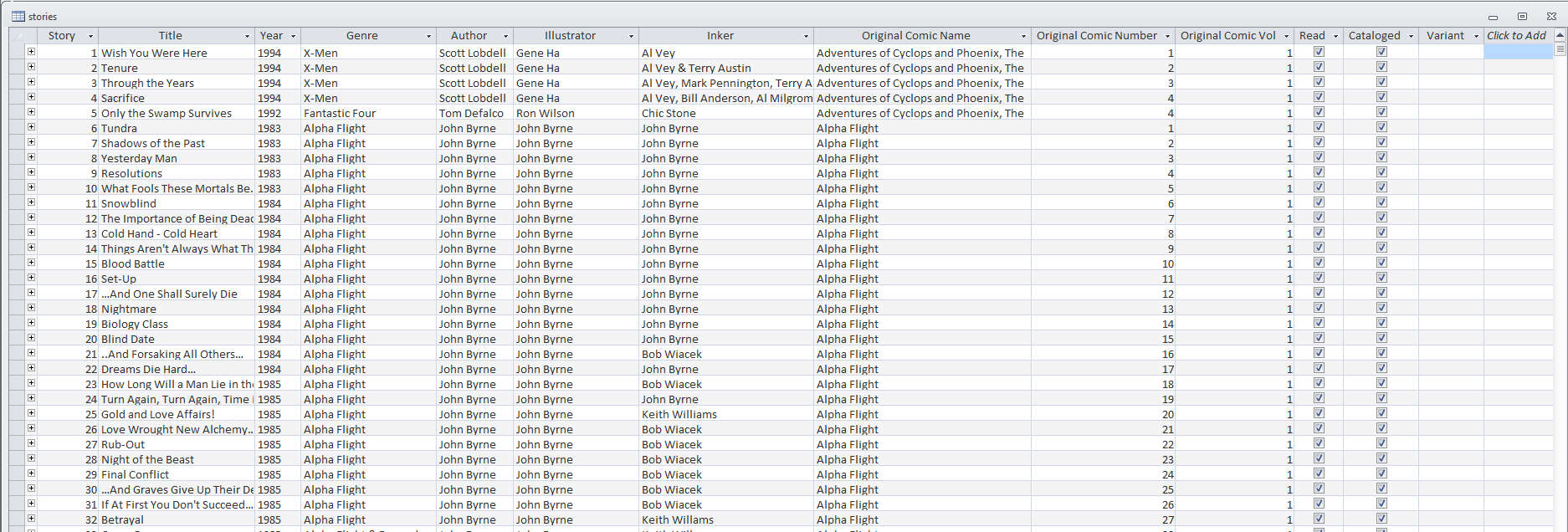
The following figure shows approximately the first 30 rows of the Story Table.
The final table is the Relationship Table which tracks the many-to-many relationships that exist between the Publication and Story tables. It has 3 fields, and the names, data types, and explanations of these fields are:
| Field Name | Type | Meaning |
| Entry | Integer | A unique relationship id label. No two relationship values can be the same, and the specific value is assigned by the DBMS unless overridden. |
| Publication | Integer | The publication id corresponding to the desired publication in the Publication table. |
| Story | Integer | The story id corresponding to the desired story in the Story table. |
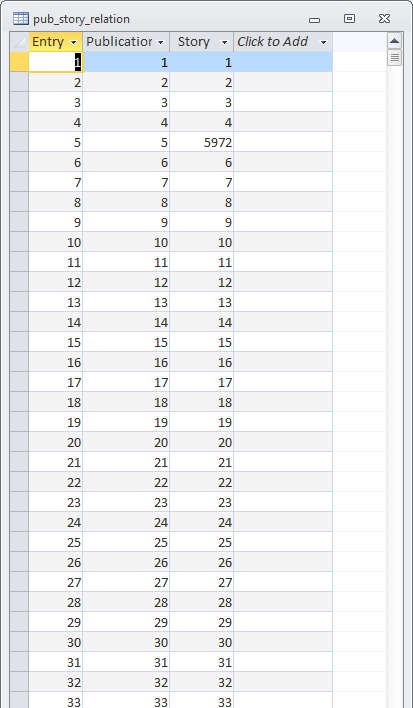
Data entry into the tables can be done in a variety of ways, but the easiest is to use a spreadsheet to get a portion of each table (say 100 publications or stories) just right, and then a bulk cut & paste to set the records in the Access table to have the same content. There are other ways for bulk data entry, but there are good web tutorials that discuss this so I won’t say anymore here. The one table where the data entry had to be done entirely by hand is the relationship table, but Access has some nice features that allow the user when editing any of the three tables to see what the relationships are to the others. These data can be accessed by clicking on the “+” on the far left of each record.
Once the tables are filled, you are ready to mine the tables for all sorts of nuggets. Mining data from the tables is done through a query where the user asks for all the data meeting a specified set of criteria. The query is done using what is called an inner join on the tables to get the desired effects, and is perhaps the hardest piece to get right, as it involves learning some of the database language known as SQL.
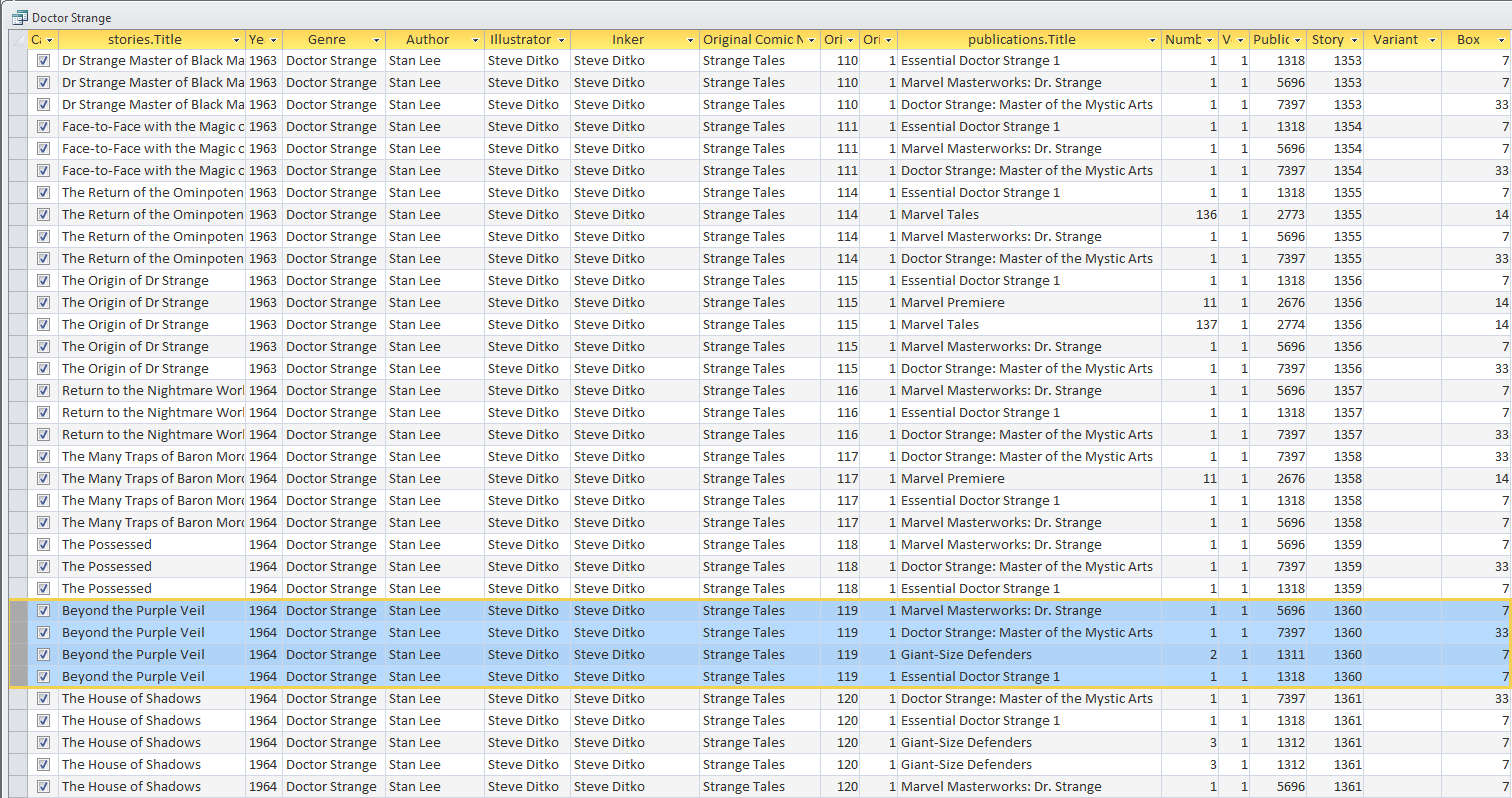
Putting in this much structure requires some time and dedication, but when it is all done you can make a list of all the comics in your collection featuring, say, Doctor Strange. The figure below shows a partial list from such a query, and you can see the multiple occurrences of the “Beyond the Purple Veil!” story.
The SQL that made this happen is:
ORDER BY [stories].[Year], [stories].[Original Comic Name], [stories].[Original Comic Vol], [stories].[Original Comic Number];
Despite its length, it is actually relatively easy to understand. The first piece is the ‘SELECT’ command, which tells the query to extract data from the fields listed. Each field is specified by its table name and then its field name using [<table name>].[<field name>]. So, for this query, 17 different fields were extracted and placed in the order specified from left to right (and if you count the number of columns in the above figure you find 17 of them). The second piece is the ‘FROM’ command that acts like a switch board to say that the data in a given row should be from a story and a publication that has relationship with each other as determined from the Relationship Table. The third piece is the ‘WHERE’ command, which tells the query to only return those records that have an occurrence of the string ‘Doctor Strange’ in them and which were published by Marvel. Finally, the fourth piece is the ‘ORDER’ command that sorts the records first by the year the story was published, then by the original name of the publication, volume, and number.
Most of the DBMSs don’t actually require you to even write SQL; the above set of commands can be constructed visually in Access using the Design View. It takes some practice, but an afternoon of experimentation and some web searches should do the trick.
Okay, what about stories that are partially reprinted in one volume. My strategy is to list the story in each of the publications. An example of this is the Warlock Special Edition (1982) #1 which contains the stories “Who is Adam Warlock?”, “Death Ship!”, and the first half of “Judgment!” from Strange Tales #178, #179, and #180, respectively. Running a query with Like “*Doctor Strange*” replaced with Like “*Warlock*” (note the wild cards) gives:

This approach works, but it is a bit awkward since it isn’t clear how much of “Judgment!” is included in one versus the other. I don’t think that this is particularly a problem since this situation happens relatively infrequently, but there is a case to be made that the Publication Table should have a field added, maybe called ‘Comments’, where these little notes can be kept.
That brings us to the ‘Variants’ field in the Story Table. That field was actually added well after the table was constructed, to address the following issue. In 1986, Marvel started reprinting the Uncanny X-Men run that started with Giant-Size X-Men #1 in 1975. Due to page count differences, the reprints appearing in 1986 had a variety of new pages added, and occasionally some panels or pages removed. Since each issue was different, the variant field is used to track the differences. For example, consider the story “The Doomsmith Scenario!” originally printed in X-Men #94 and then reprinted with modifications in Classic X-Men #2. Both stories have separate entries in the story table; the original has the Story id value of 5506 and the variant a value of 8802. They have identical entries for all the other fields except for the Variant field where the description of the modification is placed.

Additional queries that I’ve run have been to determine what publications are in each box, or how many of the comics I have have been written by Steve Englehart or drawn by Jim Starlin. Basically, once the data is in the database and the relationships are established, then any mix-and-match scenario that one can imagine can be the basis of a query.
I will end with a few additional comments on the weaknesses of my implementation. First and foremost are the names of the fields. It would have been better to call the label fields used as identifications something with the abbreviation ‘Id’ in them (e.g. Publication Id instead of Publication). This naming convention is not only a lot more precise than the one I implemented; it also prevents confusion when trying to write/design the query. Second, I might have included a series field in the Publication table. The last 10 or so years have seen publishers recycling names without incrementing the volume number, and many sites now track a comic by name, series, and year. Currently I address this by adding a qualifier in the title field itself if needed. Finally, it is easy to screw up the Genre field (which, incidentally, might have been better named Key Characters) by using similar but not exact terms – for example, Dr. Strange versus Doctor Strange. There is no really good answer for this dilemma. One possible solution is to create an approved list of character names in another table which then would have a relationship to the Story Table, but this is a very difficult undertaking. The better choice seems to be a judicious use of the wild card ‘*’ and some perseverance when making a query.