
Whether you are a long-time comic collector or you are just starting out, comic book collecting can be both fun and frustrating. The fun part should be obvious (eye popping art, mind-blowing concepts, compelling drama) but where is the frustrating part, you may ask? Well, if you own a lot of comics, organizing and listing your collection can be a daunting experience. In this column, I’ll be sharing how I used some simple concepts and a relational database to organize my collection.
Before diving in, let me say that, for the beginning comic reader today, the task of organizing a collection is much easier than when I was a beginner. I bought my first comic book in 1975 at a Kroger’s grocery store about 2 miles from my house. There were no direct sales markets and no internet. You got what you got, and often I would have gaps in the collection that would make understanding the story arc nearly impossible.
As I got older, I would visit comic shops and conventions or mail away (yes using snail mail – as I said, there wasn’t an internet) for back issues. Marvel comics were the staple back then, and I arrived at comic collecting about 13 years too late to capture the original start of the Fantastic Four, Spider-man, the Hulk, Thor, the Avengers, and the X-men. Nonetheless, Marvel kept my dream alive that I might one day be able to read the original stories through a variety of ongoing reprint series. For example, Marvel Tales helped me collect reprints of earlier Spider-man stories, and Marvel’s Greatest Comics did the same for the Fantastic Four.
There was a downside to this, though. Often these reprint titles would neglect to include a blurb saying from where the original material came, and they usually would start in the middle of the series, so that the issue number was different from the original. Occasionally, a story that was originally in one issue was split over several of the reprint titles due to differences in page count. Sometimes a reprint title would bundle multiple stories from different comics into one. Case in point, Marvel Tales #3 reprints stories from four separate comics. And, to top all this off, when they were desperate to make a deadline, Marvel would take a portion of an old story and wrap a few pages of new material around the front and back to frame it. A classic example of this technique, which I refer to as a cameo, is Giant-Size Defenders #1, which has 9 pages of new stuff interleaved with 25 pages of reprints from The Incredible Hulk, the Golden Age Submariner, and Strange Tales featuring Doctor Strange. This issue also included an additional backup reprint featuring the Silver Surfer from a Fantastic Four Annual. Confusing, isn’t it?
Today the situation is certainly better, but not ideal. Publishers in the last 10 or 20 years have tried to shape their story lines so that they fit nicely into collections, for those readers who want the stories without the bother of buying monthly or who missed the original run. They also offer a dazzling array of comprehensive reprints of classic material in publications with various price points, ranging from inexpensive newsprint (DC Showcase & Marvel Essentials) to trade paperbacks to glossy high-end, hard-cover publications (DC Archives & Marvel Masterworks).
So, if you are a fan of the stories, there are certainly a lot of choices to find what you may have missed in the first go around, but there is also a lot of opportunity for confusion in figuring out what you have and what you need. Of course, you can make lists on paper or in spreadsheets, but sorting and cross-referencing is a real hassle, and how do you make annotations for cameos and split stories. Well, the answer is a well-thought-out database schema and a relational database.
For those unfamiliar with these terms, let me give brief informal definitions and then apply them to the art of comic collecting. A database is any method of storing and retrieving data associated with some object being described. Common examples of a database include lists, spreadsheets, card catalogs, phone books, and the like. A schema is a model for how the database is laid out, usually in the form of one or more tables. For example, a phone book schema typically consists of one large table that lists the name of a household or business followed by its address and phone number. A relational database is a sophisticated software application that relates data in multiple input tables to produce new output tables that answer specific questions.
For the rest of this post, I will focus on developing a good schema for comic collecting. I’ll do this by considering a classic story that demonstrates most of the nuances encountered in organizing a collection, and show how a fairly simple schema can tame the complexity. In the next post, I’ll talk about applying this schema in a relational database, adding some finishing touches, and show the results.
The story is “Beyond the Purple Veil!” featuring Doctor Strange. Published in April of 1964, “Beyond the Purple Veil!” was an 8-page backup feature in Strange Tales 119, which was headlined by the Human Torch.

The next time this story appears is in Giant-Size Defenders #2 (1974) as one of three reprint stories backing up a 30-page new Defenders feature.
Beyond the Purple Veil appears next in a compilation entitled ‘Doctor Strange, Master of the Mystic Arts’ published in 1978 by Pocket Books. The book, which measures about 7 by 4 inches, contains reprints of the Doctor Strange backup stories from Strange Tales 110-11, 114-129, and 146, with only issue 110 identified.

It also appears in Essential Dr. Strange, a black-and-white compilation (2001), and three separate versions of Marvel Masterworks (1987, 2003, and 2010), the first and the third being hardcover and the second a trade paperback.
While it is possible to catalog each appearance of the story in a single list as separate entries as shown in the figure below, consider what happens if you notice that the title is missing the exclamation point at the end. You now have 7 entries that have to be edited, each one time-consuming and prone to error, even with a search and replace.
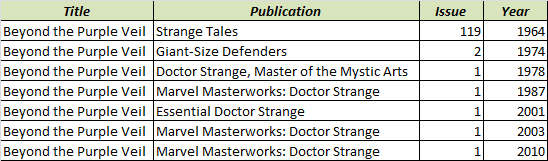
In addition, how should the other stories, contained in each of these publications, be tracked?
The simplest way to accomplish all of these goals is to have three separate lists. In the first list are all of the stories in the collection. In the second list are all the publications in the collection. The two key features of the comic collection are that multiple stories can appear in a given publication and that a given story can appear in multiple publications. This many-to-many relationship is tracked in the third list where each entry is a single relationship that indicates which story is in which publication. Taken together, the three lists constitute the schema.
The figure below shows a partial realization of the schema for the seven publications discussed above, and for the two Doctor Strange stories “Beyond the Purple Veil!” and the one that followed it, “The House of Shadows!”, published in Strange Tales #120.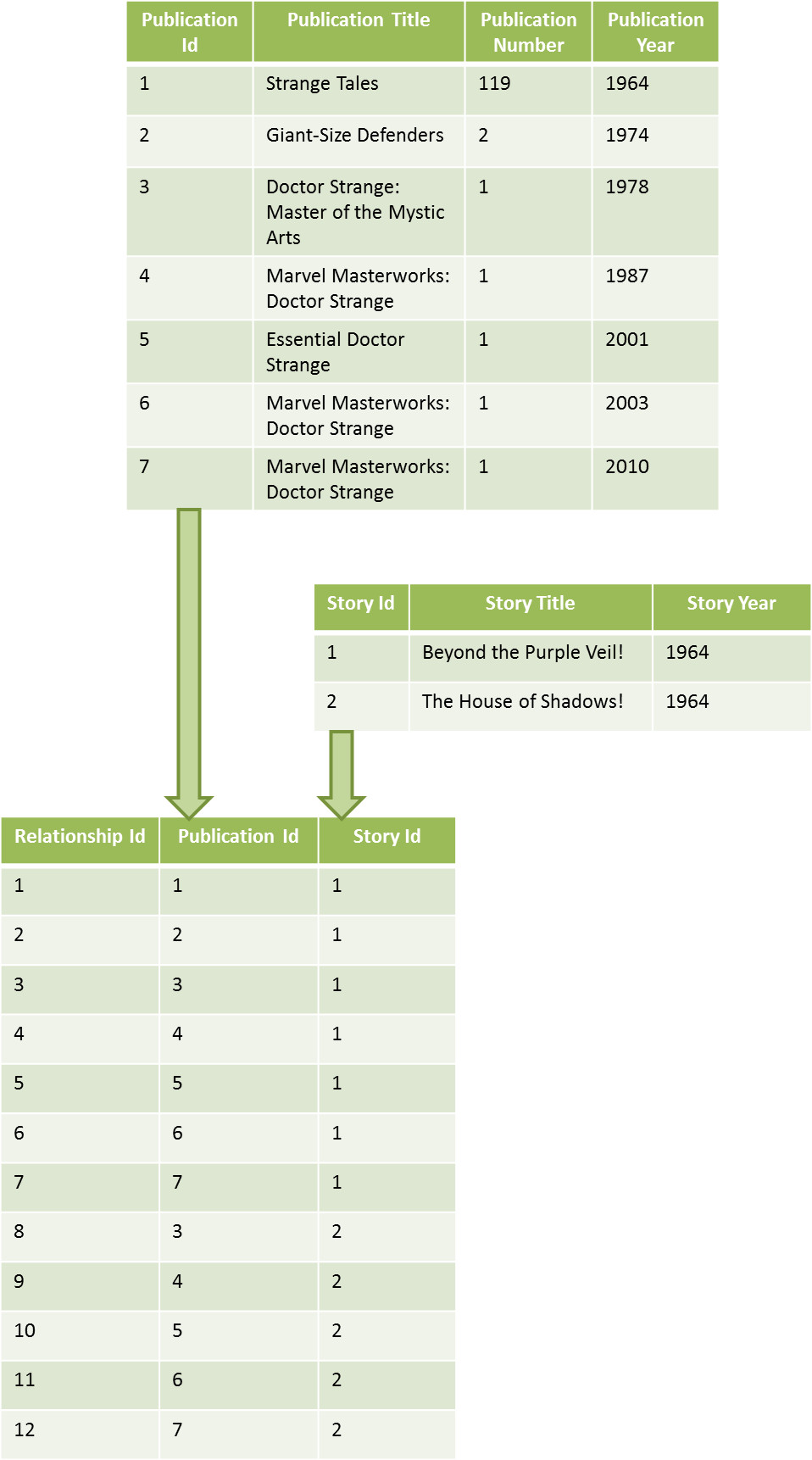
The first table catalogs the publications giving each a unique Publication Id, which is called a primary key in the language of relational databases. The second does the equivalent job for the stories. In both tables, the order of entry is not important and any shuffling of either list is workable. The third table, the relationship table, is the crucial ingredient. Each entry represents a relationship between the publications and the stories and is denoted by a unique Relationship Id. Note that the relationship table clearly reflects seven appearances of the story “Beyond the Purple Veil!” in the seven publications discussed above. Entries 3 and 8, show that the publication Doctor Strange: The Master of the Mystic Arts contains both the stories “Beyond the Purple Veil!” and “The House of Shadows!”.
That is all there is to constructing a basic schema for organizing a comics collection. Next week I’ll go into how to handle a story that gets split into more than one publication, or one that is only partially reprinted. I’ll also present how you can put some more columns in each table to track additional items, and how to mine the data to make very nice lists showing different aspects of your collection.